Maximizing Efficiency and Cost-Effectiveness
In today’s fast-paced digital environment, businesses are constantly seeking ways to streamline operations and enhance productivity. One of the most innovative solutions in the realm of cloud computing is the deployment of copilot capacities with Fabric, a powerful tool that allows companies to leverage artificial intelligence and machine learning capabilities. This blog post will delve into the various options available for acquiring copilot capacity with Fabric, focusing on two primary models: Pay-as-you-go and the Reserved 1-year plan.
Pay-as-you-go: Flexibility and Convenience
The Pay-as-you-go model offers unparalleled flexibility for businesses that require dynamic scaling of their copilot capacities. Here are some key aspects of this approach:
1. Start and Stop as Needed
One of the most significant advantages of the Pay-as-you-go model is the ability to start and stop services as needed. This means that businesses can scale their copilot capacities up or down based on real-time demand. For instance, during peak business hours or seasonal spikes, companies can increase their usage to meet the heightened demand and subsequently scale down during off-peak periods. This elasticity ensures that resources are utilized efficiently without incurring unnecessary costs.
This elasticity must be controlled via s Logic App in Azure. The capacity can be scheduled to Pause and Resume at specific time of the day. Or scale up during the working hours or scale down during the evening to save on costs. If you forget to Pause the capacity, it will be very costly. One of my MVP colleagues explain how it can be done in the article.
2. Cost-Effective for Short-Term Projects
For businesses embarking on short-term projects or experimental initiatives, the Pay-as-you-go model is particularly advantageous. It allows companies to access high-performance copilot capacities without committing to long-term contracts. This cost-effective approach means that businesses only pay for what they use, making it an ideal choice for projects with uncertain outcomes or fluctuating requirements. For example, a company might need the AI Copilot feature only for a short period of time. Creating and using a F64 capacity, the minimum capacity to get Copilot. After using it for a project or specific tasks, the capacity is Paused and does not incur compute costs.
3. Ease of Management and Chargeback
Managing copilot capacities under the Pay-as-you-go model is straightforward, as it typically involves automated billing and usage tracking. Businesses can easily monitor their consumption through comprehensive dashboards, enabling them to make informed decisions about scaling their capacities. The Microsoft Fabric Capacity Metric app is used to accomplish this.
A Pay-as-you-go capacity model can be implemented for individual departments within a company. The Fabric capacity requirements may vary among users; some larger departments might only need an F4 capacity, while others could require more robust options such as F16 or F32. By integrating a logic app to manage the scheduling of Pausing and Resuming the capacity, ensuring that it’s not left running after hours, companies can effectively control chargeback costs for specific departments.
Reserved 1-Year Plan: Maximizing Savings
For businesses with more predictable workloads and long-term projects, the Reserved 1-year plan offers substantial savings and stability. Here’s how this model works:
1. Significant Cost Savings
By committing to a 1-year plan, businesses can save as much as 40% on their copilot capacities. This significant reduction in costs makes it an attractive option for companies looking to optimize their budgets while maintaining robust AI and machine learning capabilities. If a F64 or above capacity is selected, key features like Copilot for Data Engineering, Data Warehousing or Power BI can be leveraged.
Also, F64 capacity comes with the Power BI viewer role. The Power BI viewer role is essential for organizations aiming to optimize their data sharing and collaboration strategies. By assigning this role, users can view shared reports and dashboards in Power BI without the need to purchase Power BI Pro licenses for each viewer. This capability represents a significant cost saving, particularly for businesses with a large number of employees who need to access data insights but do not need to create reports. It is also useful for users that seldom use Power BI reports or access them on an ad-hoc basis.
Cost savings are realized by reducing the number of Power BI Pro licenses, which can be substantial over time. For example, if a company has 200 employees who need to view reports, but only 10 need to create and manage them, the Power BI viewer role allows the company to purchase only 10 Pro licenses.
Additionally, leveraging the Power BI viewer role enhances operational efficiency. It simplifies user management by clearly defining roles and access levels, ensuring that employees have the necessary permissions to perform their tasks without incurring unnecessary costs. This approach aligns with the Reserved 1-year plan’s principles of predictable expenditures and enhanced performance guarantees, providing a stable financial and operational framework for businesses.
2. Predictable Expenditures
The Reserved 1-year plan provides businesses with a predictable expenditure model, which is crucial for long-term financial planning. Knowing the fixed costs associated with copilot capacities allows companies to allocate their budgets more effectively. This predictability also helps in avoiding any unexpected spikes in costs, providing a stable financial environment.
3. Enhanced Performance Guarantees
Committing to a reserved capacity often comes with enhanced performance guarantees. This ensures that businesses receive consistent and reliable performance, crucial for mission-critical applications. A data load won’t fail due to time constraints, as capacity is always available and doesn’t pause like the Pay-as-you-go model.
Choosing the Right Model for Your Business
Deciding between the Pay-as-you-go model and the Reserved 1-year plan depends on several factors, including the nature of your workloads, budget constraints, and business objectives. Here are some considerations to help you make an informed decision:
1. Workload Predictability
If your business experiences fluctuating workloads or engages in numerous short-term projects, the Pay-as-you-go model may be more suitable. It offers the flexibility to adjust capacities in real-time, ensuring that you only pay for what you use. Conversely, if your workloads are more predictable and stable, the Reserved 1-year plan can provide significant cost savings and performance guarantees.
For a large number of users who occasionally access reports but don’t create them, the F64 1-year reserved is your best option.
2. Budget Constraints
For businesses with tight budget constraints, the Pay-as-you-go model allows for more controlled spending, as costs are directly tied to actual usage. Numerous small businesses require data loading, transformation, and reporting but often lack the budget for a year-long reserved plan due to fluctuating capacity needs throughout the year. For such scenarios, the Pay-as-you-go model proves to be the most suitable option.
However, if you have the financial flexibility to commit to a longer-term plan, the Reserved 1-year option can offer substantial savings, freeing up resources for other critical areas. The 1-year reserved plan is not limited to the F64 and above capacity. The savings also apply to lower capacity like F2, F4, F8, F16 and F32.
3. Strategic Initiatives and price evaluation
Consider the strategic initiatives your business aims to undertake. If innovation and agility are at the forefront, the Pay-as-you-go model’s flexibility may best support rapid experimentation and scaling. On the other hand, for businesses focused on stability and long-term growth, the Reserved 1-year plan’s cost savings and performance guarantees can provide a solid foundation.
To get an overview and give you a better idea of what is the best option for you, the Azure Pricing Calculator can be used. You type Fabric in the search box and choose the Microsoft Fabric option as shown below.
You then choose the Region, Compute Sku (capacity) and pricing model. For example, choosing a F64 capacity for 730 hours (1 month) costs USD $8409.60 with no upfront costs.

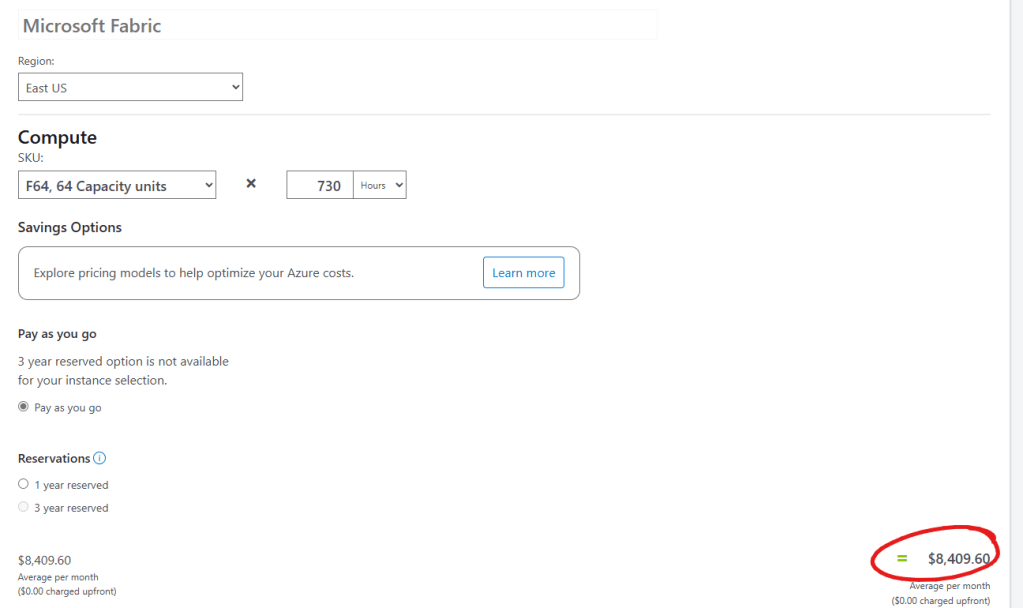
If we choose the Pay-as-you-go model, we want to Pause and resume the capacity upon our usage. The same F64 capacity cost would be reduced to USD $1152.00 if we use it only 100 hours per month (12 days approx.)
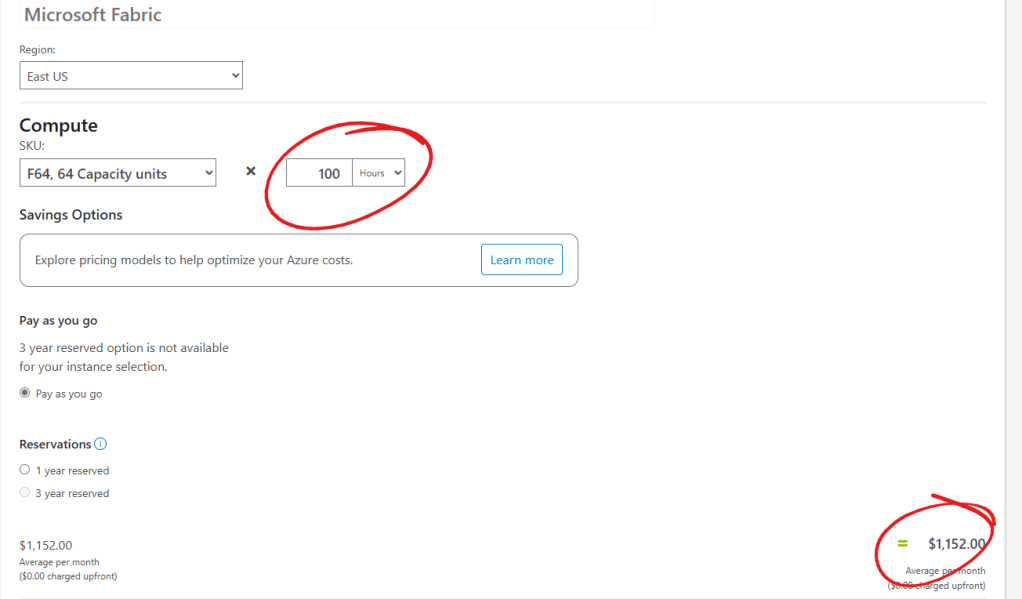
But if we use the 1-year reserved plan, the price reduction is quite interesting: USD $5002.67.
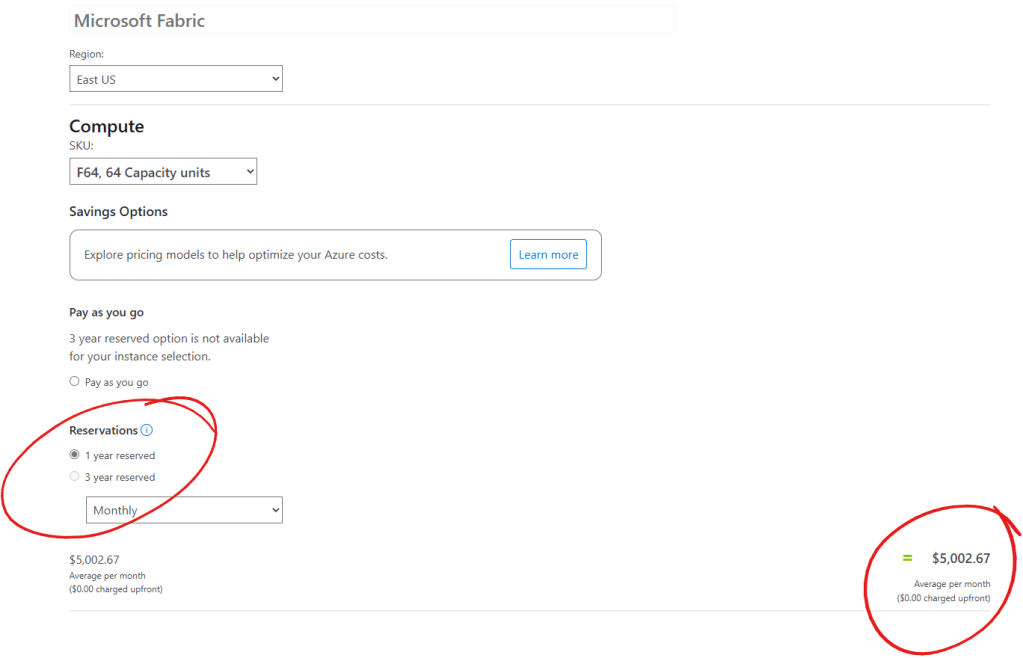
We can choose the 1-year reserved option for lower capacity as well. Prices differ by region, so ensure you select the correct region before estimating costs.
Conclusion
Both the Pay-as-you-go model and the Reserved 1-year plan offer distinct advantages for obtaining copilot capacities with Fabric
As you consider these options, keep in mind that the goal is to leverage copilot capacities to their fullest potential, driving innovation and achieving excellence in your business operations. Whether you opt for the flexibility of Pay-as-you-go or the savings of a Reserved 1-year plan, the key is to remain adaptable and responsive to the ever-evolving demands of the digital age.












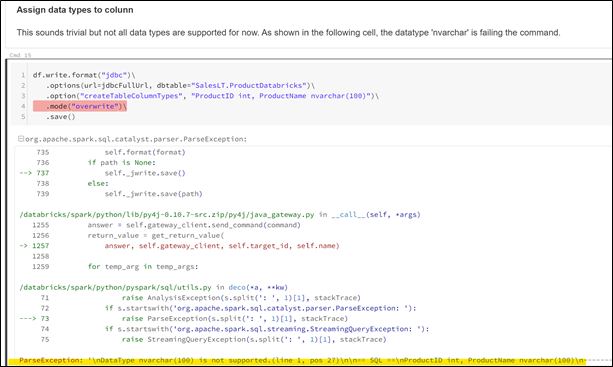
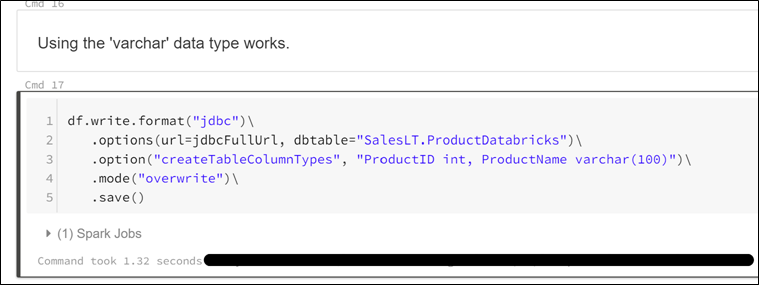
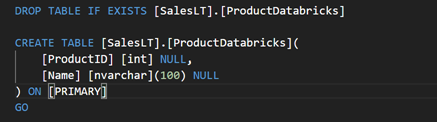
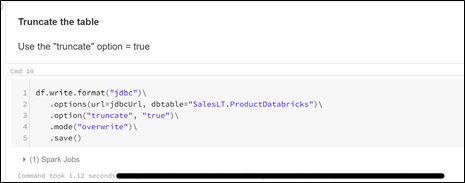
 data type mapping in Databricks")