SSIS data flow are very powerful and can sometime be very complex and long. Therefore, like any other programs, we would like the ability to comment sections of the data flows. This post will describe various way to d this.
Annotations
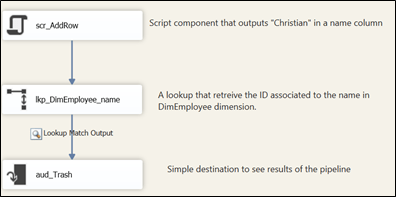
The obvious way to add comments or notes is to use annotations. Annotations can be used everywhere in a package, control flow, data flows and event handlers. There are efficient and easy to move around everywhere in the package.
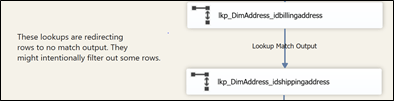
Figure 1
Now, one feature I like a lot in SSIS data flows is the ability to re-arrange data flows objects by using the “Format”à“Auto Layout”à“Diagram” command from the top menu. This align objects correctly most of the time.
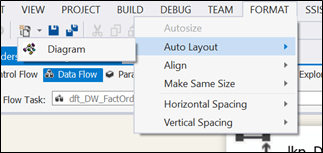
Figure 2
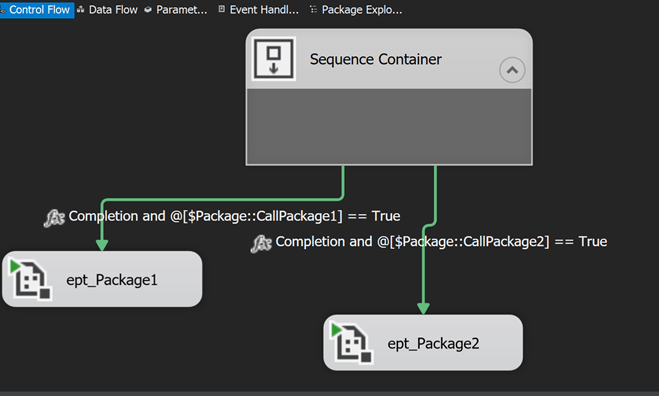
Now, when it comes to annotation, it doesn’t work properly. As you can see in Figure 3 below, the annotation has moved at the bottom of the package. If we had used many of these annotations, how can we know what transform(s) they belong to? As of now, there’s no way to tie an annotation to specific transforms. There is a connect issue that was closed in 2010 that relates to this issue.
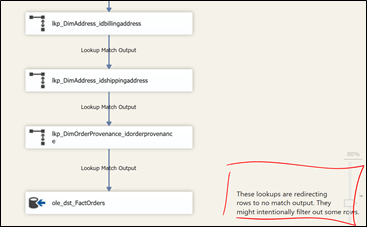
Figure 3
Objects grouping
Since SSIS 2012, we now have the ability to group objects in a data flow. We can therefore group the annotation with the lookup and get something similar to Figure 1 above. This gives us something like Figure 4 below:
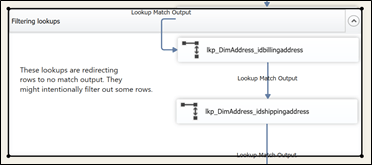
Figure 4
Then, using the “Format”à“Auto Layout”à“Diagram” command from the menu will also format the grouped objects but at least, they are still grouped. However, the group will now be moved to the bottom of the data flow.
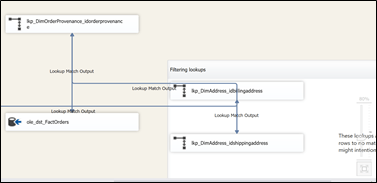
Figure 5
So, we’re now back to square one basically.
Path annotation
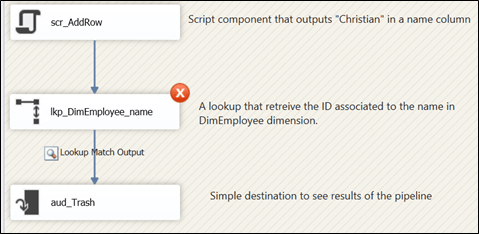
Another option we have and it might be useful is to use the annotation property of the various paths. The regular paths underneath the lookup have “Lookup Match Output” assigned by default.
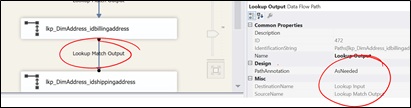
Figure 6
This is due to the fact that (as shown in Figure 6), the “PathAnnotation” property is set to “AsNeeded” and by default, it displays the “SourceName” property. We can’t change the “SourceName” property, it is read only. But we can change the “Name” property though.
In Figure 7 below, I changed the “Name” property and set the “PathAnnotation” property to “Name”.
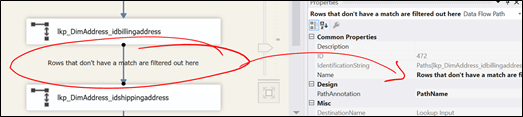
Figure 7
Now, instead of having “Lookup Match Output”, we have a more descriptive path annotation.
Objects “Description” property
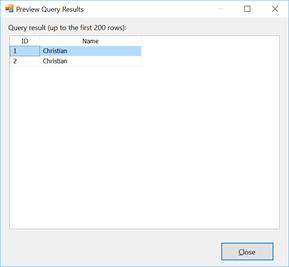
Another way of commenting our data flow transforms or control flow tasks is to use the “Description” property of every objects you want to comment on. To see the content of the “Description” property, we have to hover with over the object we want to see the description as shown in Figure 8.
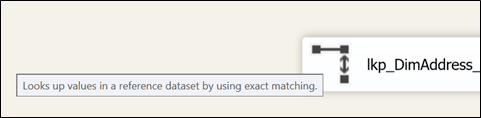
Figure 8
By default, we have “Look up values in a reference dataset by using exact matching.”. We can change this using the property pane. Therefore, we’ll now see whatever we typed in the description of the object.

Figure 9
This might be useful to see what’s happening in the designer but the downside is that we can’t really know if a comment exists unless we hover the mouse over it.
To sum up
As useful as annotations are, they cannot be tied to a specific task or transform. So every time the task or transform moves, we have to carry the annotation manually.
Grouping helps but it takes significant space on the package.
Path annotation gives us more flexibility because we can see the annotation on the package, it is tied to it. Also, the name can be referred in the execution reports and log because we changed the name of the path. Still, it looks like a hack though.
Description is another option but are only visible when we hover the mouse on the object.
If Microsoft could let us tie annotation to a specific object, it would resolve many issues we talked in this post. Let’s hope they fixe it in future versions.








 L’agenda est disponible en suivant ce lien :
L’agenda est disponible en suivant ce lien : 