 data type mapping in Databricks")
When using dataframes and save it to SQL Server using JDBC, the resulting data type for a string column is nvarchar(max). This happens when let JDBC creating the table without supplemental instructions. We seldom need to have our string columns using with this data type as it limits the functions we can use with it such as substring().
This article will show some options to avoid having a nvarchar(max) column in our table
A simple query
First thing first, we’ll connect to a database. For this article. I am using a sample database; AdventureworksLT from Microsoft Git web site. With Databricks, we connect to the server using JDBC and query the “SalesLT.Product” table to bring back two columns:
- ProductID: integer column;
- Name: navarchar column, it will be seen as a string in the dataframe;

Now that we have retrieved data in our dataframe, we’re going to save it back in a different table. In real life, we would have transformed the data quite a bit but yhe goal of this article is to explain how to save a dataframe back to SQL Server with correct data types.
Save the dataframe; the simple way
The first thing we will do is to simply save, overwriting the destination table. Overwriting the table without any other options means we are going to drop and recreate the table.

The resulting table structure is shown below. I did the screenshot with Azure Data Studio. As we can see, the “ProductName” column’s data type is nvarchar(max). This is not the best option but, it ensures that whatever is stored in the dataframe’s string column will fit; it’s a safe choice.

There’s a way to specify the data type of the dataframe’s columns while saving it to the database. But in order to find the right length, we need to profile the data. Still in Databricks, we’ll find the maximum length of the “ProductName” column in our dataframe as shown below.
Specifying a data type

Now that we know the maximum value in the column, we use the “createTableColumnTypes” option when we save the dataset. However, specifying “nvarchar(100)” fails. The “nvarchar” data type is not supported for now.

Using the “varchar” data type executes successfully as shown below.
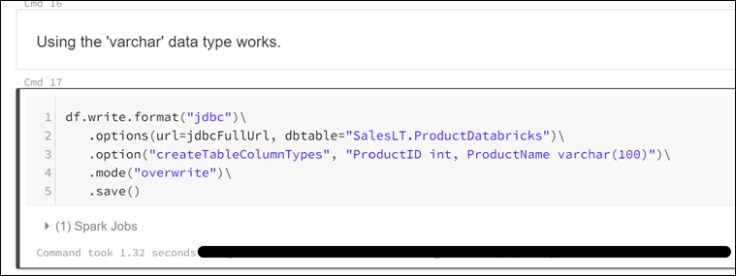
When we look at the table structure in Azure Data Studio, we clearly see that the command created a table with the specified structure.

However, I am not satisfied with it. I dislike using “varchar” data type as we live in a connected world now and sooner or later, this data type will limit us with international character sets. To circumvent this, we have to create the table first as shown below.

Truncate the table
Next, we’ll use the “truncate” option with the save command. This will NOT drop and recreate the table but simply empty (truncate) the table.

Going back to Azure Data Studio, we notice that the table’s structure has not been altered by the save with overwrite command.

But we have to be careful because if the structure of the dataframe changes by adding/renaming a column, the command will fails as shown below.

To sum up
There are some valid options to avoid be stucked with a “nvarchar(max)” column while saving a dataframe with Databricks An improvement I would like to see is the support for “nvarchar” data types. This might come in a near future.

Leave a comment