
AT my client’s place we’re using Databricks in conjunction with Azure Data Factory to transform data coming from HTTP connections. These connections data end up in an Azure blob. When we’re receiving JSON data, Databricks and most Azure components knows how to deal such data. Databricks have JSON libraries already available for us to use.
We start receiving XML files from a provider lately. Using Databricks, I thought that I would be able to load the data in a data frame as easily than I am doing with JSON from the Azure blob storage. Here’s the command I use in Python to load JSON data:
df = spark.read.option(“multiLine”, True). json(completeFilePath)
The command tells Databricks to load my “completeFilePath” content from my blob storage into a data frame called “df”. I use the “multiline” option because the JSON data is spanning on multiple lines.
Naively, I thought that reading an XML file would be as easy. I just have to issue a command like the following in Python:
df = spark.read.option(“multiLine”, True). xml(completeXMLFilePath)
Unfortunately, this is not that easy. There’s no native XML library available with Databricks when we create a workspace. We need to load one. After some research on the web, I found this link on Github: https://github.com/databricks/spark-xml. In the document, we can download the library and we need to load it in the notebook. Here are this instructions on how to refer to the libfrary in the notebook.
Spark compiled with Scala 2.11
$SPARK_HOME/bin/spark-shell –packages com.databricks:spark-xml_2.11:0.4.1
From a Databricks notebook perspective, this is not obvious how to attach the library to it. We cannot use this code anywhere in the notebook. I don’t pretend to be a Databricks expert though but even when I looked at the cluster configuration, I could not find a way to attach such library as shown in the following screenshot
Even not from the Libraries tab:
Doing more research on the web pointed me to the right place. From the notebook folder menu, we click on the drop down arrow, select Create and then Library from the submenu that appears as shown below.

The following screen appears. Select Maven Coordinate as source and click on the “Serach Spark Packages and Maven Central button after.
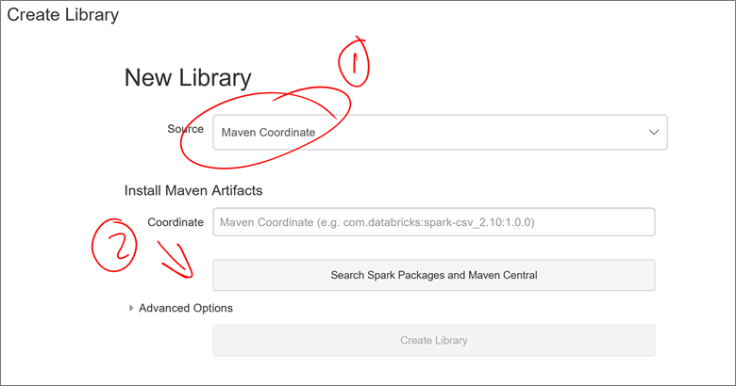
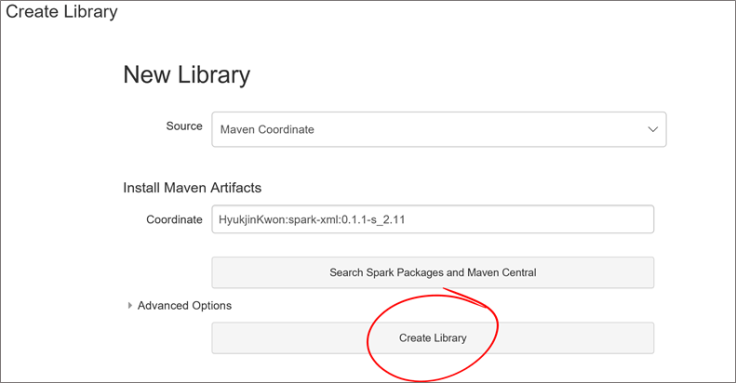
From the search page, type “xml” and click on the search magnifier icon as shown below. From the list that appears in the center, select “spark-xml”, choose the release that matches your cluster, 2.11 in my case and click on “+ Select” right beside it as shown below.

The screen close and you’re back to the “Create Library” screen. Click on the “Create Library” button at the bottom of the screen.
The next screen allows us to attach the library to a cluster. Click on the “Attach automatically to all clusters.” If you want to be able to use it with any cluster you create whether it’s a job or interactive cluster. Since we’re calling our notebook from Azure Data Factory, it’ll be a job cluster. This checkbox has to be checked for us.

When we select the checkbox, we get a confirmation window, click on “Confirm”. You should see that the library is attached once done.

Going back to the Cluster’s library tab, we now see that the library is attached to it.

Voilà! The library is attached and ready to use. From our notebook, we can now load a file any issuing the following command:
df = sqlContext.read.format(‘xml’).options(rootTag=”‘<my root tag>”).load(completeXMLFilePath)
And the dataframe “df” gets loaded with the “completeXMLFilePath” file content from our blob storage.
Hope this article will save you some time as I spend a couple of hours to find out how to attach the XML library to my clusters.

Leave a comment