Azure Data Factory (ADF) is always improving. This post will talk about how the editor has improved since its introduction.
SHIFT+F10, get the help menu
Pressing SHIFT+F10, the following menu appears.
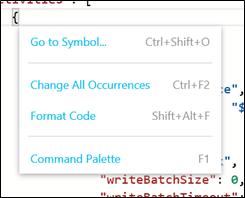
From the image above, you can see that several commands are available from this menu:
- Go to Symbol: displays a list of elements in the JSON that you can access when selecting an element from the list.
- Change All Occurrences: as it indicates, will change all occurrences of a specific element that you selected.
- Format Code: this command will correct indentation and align the code correctly for you. If you close an artifact and re-open it, the code formatting is applied de facto.
- Command Palette: this command will display the available commands in ADF. Even though the shortcut key is F1, it doesn’t have the same behavior as on-premises program; it will not open another browser or tab in the browser that displays the documentation. It only provides a list of commands.
Go to Symbol
This command allows you to navigate faster inside the JSON document. Press SHIFT+F10 and choose go to symbol from the menu.
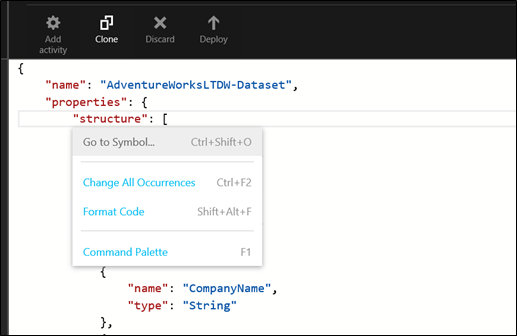
A list of objects present in your JSON document appears:

You can see in the upper right corner of the sub-menu how many symbols your document has. Now we’ll navigate to an element “Availability” in the document:
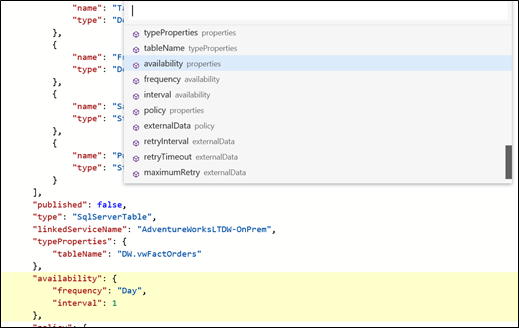
Using the keyboard down arrow, when we navigate in the list, the specific symbol is highlighted. Now, clicking on it with the mouse or pressing enter on the keyboard will move the cursor to the symbol:
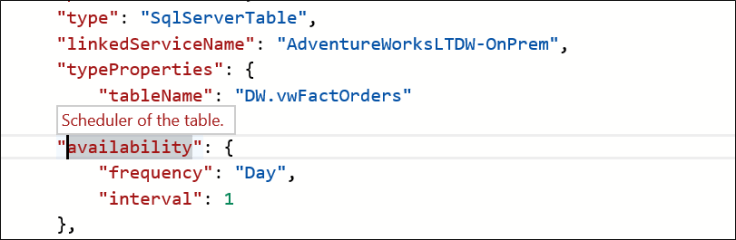
Notice that the symbol is selected and its definition or contextual help is displayed above it.
Change All Occurrences
This command allows you to rename all occurrences of a specific symbol.
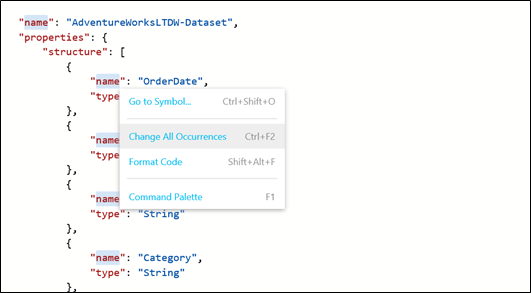
In the example below, we’ll change all “name” symbols to “test”. It doesn’t make sense to do it in the real life but I do it only to show you how the command would work.

In a real world scenario, you would use this command to rename multiple occurrences of structure element’s name.
Format Code
This command I really simple, it will reset the code formatting to make it more readable. For example, let’s say we mess a lot with our structure elements.

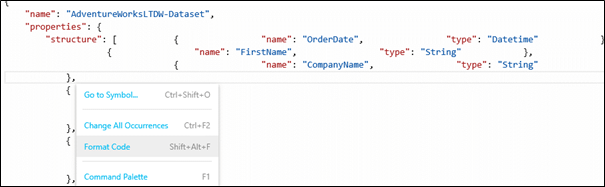
Using “Format Code” command will re-format the JSON structure:

Command Palette
This feature is a kind of help since it shows you all available commands of the editor.
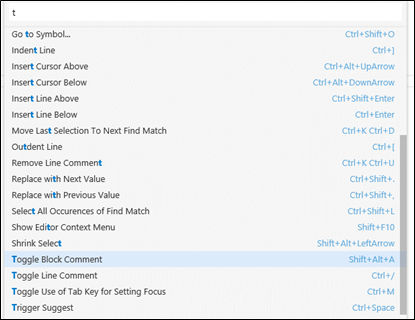
As you can see, there’s a textbox at the top that allows you to search for specific command. I typed the letter t and all commands that contained that letter are now displayed.
IntelliSense
Now, let’s see how we can use intelliSence in ADF. Like any .Net language, intellisense can be triggered by typing CTRL+Spacebar. For example, when we type structures in datasets using the ADF editor, we simply have to type: na without completing the word to “name”. Press on TAB and voila, itelliSense corrects the tag for us.

When it comes to the datatypes, starting to type the name of the datatype will make a list of datatypes containing what we have just started to type.
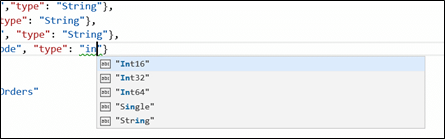
So now it’s easier to create our structures in datasets. Structures are important for several reasons and I’ll explain them in a future post.
Validation and help
The editor also validates as we are typing. For example, we need to have a type in a structure of a dataset. Failure to provide one will lead to error when we’ll try to publish the dataset. In the image below, I highlighted the uncompleted structure element.



In the case above, it’s clear that we have to provide a valid data type for the element.
Another example is when external policies are used in the dataset. If one of the policies is not correctly provided, ADF editor will show a warning (green underline) where there’s missing or non-conform data.



As shown in the above screen clip, we are provided of what the property should look like and the description of the property.
To sum up
Azure Data Factory editor has gone a long way since i’s introduction at the end of February. There are remaining caveats like the fact that intelliSense won’t list user created objects in various artifacts. For example, in a pipeline, it would be nice that the input or output of an activity:
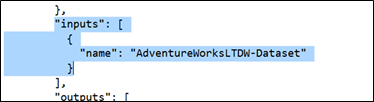
In the above code, I highlighted what I would like the editor integrate in intelliSense; the capability to list available datasets (in that case AdventureWorksLTDW-Dataset). We don’t have this possibility for the moment. Probably in the future though. Anyway, I hope so J.
Anyway, I’m sure that everyone that uses the editor will be more productive with these enhancements.






 L’agenda est disponible en suivant ce lien :
L’agenda est disponible en suivant ce lien : 
