The new GDR for Visual Studio Team System for Database Professional (VSTSDBP) now includes a command line utility. You can now generate a schema files from the source db or deploy dbschemas to target db whitout VSTS4DBP. In fact, the utility can be used by simply copying the executable and a bunch of assemblies to a thumb drive.
It gives us the following possibilities:
– reverse engineer a database on a server or
distant machine and bring the result file
(.dbschema) file with us. This way, we can
copy the dbschema file to a machine that
has VSTS4DBP and analyze it by doing
schema comparisony or static code analysis
on it.
– bring the dbschema file to another server or
distant machine in order to deploy it.
In summary, VSDBCMD.exe gives VSTS4DBP users a very useful portable
utility. In a future post, I will dig a bit more on how it can be used. I will show some samples and screen captures in order to better demonstrate what the tool can do.
Stay tuned!
Visual Studio Team System for Database Professional
I began using this tool last year and I fell in love with it almost instantly. Briefly, this tool allows you to:
- Script your SQL Server database and put scripts under source control. This is useful when you to know precisely which version of a specific database object (table, stored procedure, etc.) was deployed with version n of an application.
- Manage databases in the same tool (Visual Studio) that you use to develop your applications.
- Deploy the database (either completely or incrementally) to specific servers from Visual Studio. You can also use build your database project, which produce a SQL file, and send it to DBA for deployment.
- You can have pre and post deployment scripts that permits specific actions ( create logins, assign DB roles, insert medatada into static tables, etc.). These scripts are embedded into the final SQL script for deployment.
- Generate data for testing purpose. With power tools installed, get specific data from another database or server in order to give developer valid data for development.
- Generate unit tests for stored procedures. Combined with data generator, you could deploy a database and test its stored procedures immediately.
- The project is known as the truth version of the database. It's very helpful when you want to deploy the database on other environments or servers. You do not have to rely on production database, reverse engineer objects in order to have the right version.
I will blog more on it in future posts. So, if you are interested, stay tuned! 😉
Labels: VSDB
Indirect VS Direct configuration
Recently, I blogged about Indirect configuration with SSIS. In the first SSIS project I did, I questioned myself, search through web sites, to find out whether I should use direct instead of indirect configuration. Here are the pros and cons of direct and indirect configurations.
Direct configuration
Pros:
- Doesn't need environment variables creation or maintenance
- Scale well when multiple databases (e.g. TEST and Pre-Prod) are used on the same server
- Changes can be made to the configurations files (.dtsconfig) when deployment is made using SSIS deployment utility
Cons:
- Need to specify configuration file that we want to use when the package is triggered with DTExec (/conf switch).
- If multiple layers of packages are used (parent/child packages), need to transfer configured values from the parent to the child package using parent packages variables which can be tricky (if one parent variable is missing, the rest of the parent package configs (parameters) will not be transferred).
- The two above cons can be bypassed by using SSIS deployment wizard, so if the configuration file switch (/conf) with DTExec is not used, packages need to be deployed via SSIS configuration wizard
Indirect configuration
Pros:
- All packages can reference the configuration file(s) via environment variable
- Packages can be deployed simply using copy/paste or xcopy, no need to mess with SSIS deployment utility
- Packages or application is not dependent of configuration switches when triggered with DTExec utility (command line is much simpler)
- Multiple layers (parent/child levels) scale better since all packages has all configuration values it needs to execute. They do not depend on parent packages and a child package can be used as a parent packages without problems (no need to remove or add parent packages configurations
Cons:
- Require environment variables to be created
- Does not support easily multiple databases (e.g. TEST and Pre-Prod) to be used on the same server
Using multiple package set on the same server
While this is not current, it happens sometime that the same server is used for both Test and Pre-Production. Using indirect configuration, An environment variable holds the reference to a configuration file. Since there are multiple databases or package set on the same server, indirect configuration cannot be used with system environment variables.
This problem can be circumvented by using user environment variables, but this is more complicated since it requires more than one user to be created to be able to launch loads. Also, remote desktop if often used to enable developers to connect onto test/pre-prod servers for debugging or deployment purposes using their active directory (AD) account. This approach would require multiplying AD accounts by the number of databases on the server.
Another approach would be to isolate databases by using virtual machines. But, with high volume ET loads, adding another layer between OS and package set can fool performance and tuning statistics and therefore strategies used to improve overall load performance. That said, having a slower machine while testing force developers to improve their packages loading performances, which cannot be harmful when deployment of the application onto production server :-).
Which method should you use?
The answer to this question is: it depends. If you are confident that you are going to use the same path to store your configurations files in Dev/Test/Pre-prod and production servers, direct configuration is an option.
The most flexible approach is definitively the indirect configuration. Using this method, you can change configuration file location and even its name. Also, I like having my packages behave like business objects: that is they the necessary logic to access what they need to function properly. A package know where to look to find out its core configurations (connection strings for example). It does not rely on parent package for them.
I hope this article help some of you decide which configuration method to use. On all the projects I did ( or doing), I always need to think of which method to use. It always depend on the architecture and deployment method used in place. But, when I have the choice (nothing has ever been done yet), indirect configuration is my first choice.
Using indirect configuration with SSIS

SSIS has a great feature called indirect configuration. It is used to store the configuration access path into the computer’s environment variable. This feature greatly facilitates the deployment of an SSIS solution. All you have to do is to set the environment variable on the target computer and all packages in the solution automatically points to the right place.
Configurations are at the very heart of SSIS packages. They are used to set specific properties to packages objects. 5 configuration types are available within an SSIS package:
- XML configuration file: an XML file (.dtsconfig) is created in the folder you specify.
- Environment Variable: The property of the package object is set to the value of the chosen environment variable.
- Registry Entry: The property of the package object is set to the value from a registry.
- Parent package variable: Used to pass parameters from a parent package variable child package object property.
- SQL Server Used to initialize a package objects property from a SQL Server configuration table (this will be explained in a subsequent post).
All of these configuration types, except one, have another option button at the bottom of the package configuration wizard window “Configuration location is stored in an environment variable”। This enable to refer to the configuration file(।dtsconfig), registry entry, parent package variable or SQL Server table connection string using the value of an environment variable. The only exception in the list is the Environment variable configuration: since we already specify that the package property object is set via an environment variable, it is then already using indirect configuration.
A practical example on using indirect configurations
The best way to demonstrate the indirect configuration usage is to build an example। Start business intelligence development studio (bids) and choose “Integration Services Project” from the New project templates। Give a name to the project and if rename “Package.dtsx” in the solution explorer to “Indirect configuration example”. Click “Yes” when asked to rename the package object as well. The last action causes the package name to be renamed as well as the package file name.
Next, create a connection manager: in the connection manager’s window at the bottom of the package window, right-click into it and choose “New OleDB connection”. Click New, the connection manager window appears: 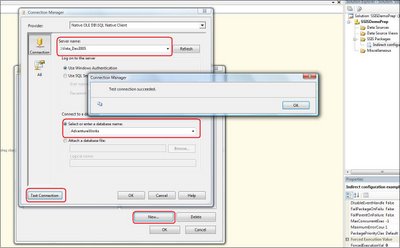
Choose your server from the “Server name” combo box. Make sure that “Use Windows Authentication” radio button is selected then choose “AdventureWorks” database from the “Select or enter a database name” combo box. Click then on “Test Connection” and a message box appears confirming that the test connection succeeded. Rename the new connection manager “cmgr_AdventureWorks”. The prefix is part of a naming convention I use. Having a naming convention is very useful because it helps to categorize different package’s objects and it makes it easier to parse a log file when, for example, a load is running or has crashed.
On the control flow of a package, select SSIS in the menu bar then choose “Package configurations”. The package configuration appears. Check the checkbox “Enable package configuration” then, click “Add” at the bottom of the window. The “Package Configuration Wizard” window appears
 From the “Select Configuration Type” page, choose “XML configuration file”. Type cfgn_AdventureWorks in the “Configuration file name” textbox. Click on the “browse” and then the “Save” buttons. This will create a XML configuration file named cfgn_AdventureWorks.dtsConfig in the project’s folder. Click on the “Next” button.
From the “Select Configuration Type” page, choose “XML configuration file”. Type cfgn_AdventureWorks in the “Configuration file name” textbox. Click on the “browse” and then the “Save” buttons. This will create a XML configuration file named cfgn_AdventureWorks.dtsConfig in the project’s folder. Click on the “Next” button.
The next wizard’s page “Select Properties to Export” enables us to export (store) multiple properties values into the configuration file. Since we only want to set the connection string of our connection manager, in the treeview at left, expand Connection managers, cmgr_AdventureWorks, Properties then check ConnectionString property. Click on the “Next” button. Give a name to your new configuration: cfgn_AdventureWorks then click on the “Finish” button.
Browse to your project folder and double-click on the file named “cfgn_AdventureWorks.dtsConfig. Your file should look like this:
 Some information’s specific to my computer and SQL Server instance will be different in your file.
Some information’s specific to my computer and SQL Server instance will be different in your file.
Using indirect configuration
Ok, now we have a DIRECT configuration. Our package references the full path of our configuration file. That’s not exactly what we want since once our package will be deployed, it's more than likely that the configuration file will be in the same location (drive, folder, etc.). To circumvent this behavior, we need to make our package to get its connection information (the configuration we just created) in a more generic way: we are going to use an environment variables – we are going to have an INDIRECT configuration.
First of all, we need to create an environment variable. But you need to be aware that our new environment variable won't be visible for our SSIS package or project if BIDS is opened before we create the variable. So, if BIDS is opened, close it.
There are two type of environment variables:
- System: these variables are available to all users that log on the computer.
- User: these variables, as the name of the type implies, are available to the user that create them and log on the computer.
SSIS is able to see both types. It is just easier to use system environment variables since all users can use them. Especially on a server. Several process could use it.
Also, there are several ways to create environment variables. My favorite way is using the "Setx" command line.If your operating system is Windows XP, you will have to download Windows XP SP2 Support Tools Then, at command prompt, type:
Setx cfgn_AW_Path C:\MyProjectFolder\cfgn_AW_Path.dtsConfig -m
The -m option will make the environment variable "System". Now, open another command prompt window and type :
set cfgn_AW
Your screen should look like this: 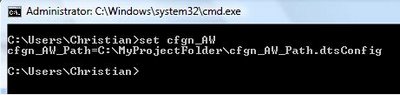
Now, start up BIDS again and open your project. Open your package, right-click in the control flow and select "Package Configurations" from the popup menu. Now Edit your configuration that we've created earlier. Select the “Configuration location is stored in an environment variable” and then choose the cfgn_AW_Path environment variable.
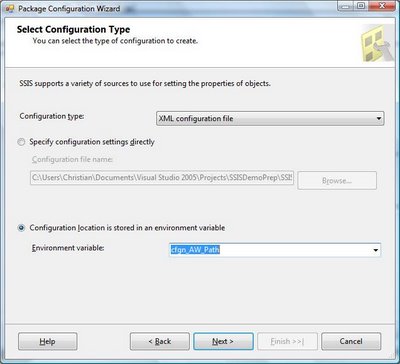
Click "Next" and "Finish" and voila, your package reference your dtsx configuration file via an environment variable.
This article showed you how to use indirect package configuration. By using this type of configuration, you can change the location of your configuration files and even rename them. All of this will be transparent to your packages.
Labels: Intermediate SSIS
