
While writing an article earlier on how we could have comments in SSIS, I noticed a property I had never noticed before: we can have a lookup failing when there are duplicates in the reference set.
Suppose we have a small package like the one in Figure 1
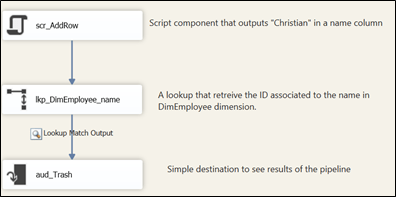
Figure 1
We have a source and a lookup, the lookup simulates a dimension that would have duplicate reference column values. Here js the reference set returned by the dimension.
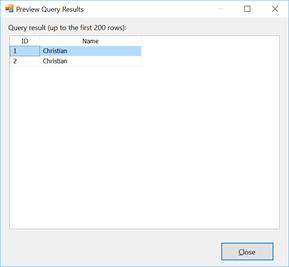
Figure 2
The name “Christian” appears twice with two different ID’s. This should never happen in dimensions but it might be the case that we have other columns that makes the row unique e.g. different last names. But in the example above, I intentionally wanted to have duplicate values for the purposes of this article. The lookup column matches on the name column and returns the ID associated. Figure 3 is taken from the “Columns” tab in the lookup “lkp_DimEmployee_name” shown in Figure 2.

Figure 3
What happens when we have duplicate reference values (“Christian” in that case) is that SSIS will issue a warning at the execution of the package. Here is the warning from the execution pane in SSIS:
[lkp_ DimEmployee _name [5]] Warning: The lkp_DimEmployee_name encountered duplicate reference key values when caching reference data. This error occurs in Full Cache mode only. Either remove the duplicate key values, or change the cache mode to PARTIAL or NO_CACHE.
SSIS is warning us that the ID might not be consistent from one execution to another or it might not be able to find anything due to the fact that there are duplicate value in the column we use to lookup the ID. It can return 1 or 2 depending on several factors like how many rows we retrieve from SQL Server and in what order SQL Server will read those rows. Let’s say that we want to retrieve the first row only and that first row is the one that has the minimum ID. Since lookups return only one row, we simply have to order our reference set by ID. Something like “ORDER BY ID ASC” in our select statement. We would be sure that we retrieve consistent result every time.
But our problem is that we have duplicate references, two time the name “Christian” and this might lead to errors in data analysis down the road. Having such duplication is might be considered as a fatal error in data warehouse loads. Therefore, the is a lookup property that will fail the package if we have errors in our reference set.

Figure 4
This property is set to False by default and we simply get a warning like the one highlighted above when there are duplicates in the column used as a key in the lookup reference dataset. If we set it to True, the package will fail at execution no matter if we set the “Specify how to handle row with no matching entries” because the reference set is evaluated before dataflow execution, while the lookup cache is built (Figure 5).
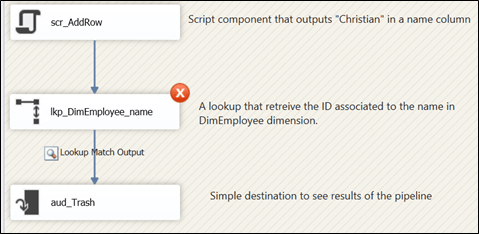
Figure 5
This setting prevents misinterpretations of key assignment; the data flow will fail before executing, period. This might be annoying but it would be easily avoidable if we do some data cleansing or tune up our lookup query. It’s never good news when we have more that one values for one of our key columns that should be unique. SSIS helps us to prevent errors at key assignment and this lead us to have accurate results in our data warehouse!
